Spring Boot - Implementing a Distributed Task Scheduler (without queue)
When developing a service, one of the challenges you could face is the need to execute tasks that run automatically and periodically. Those tasks could contain undefined and/or unpredictable amounts of work and load, so the need to have a scalable architecture is strong.
Limiting the implementation of this challenge to simple @Scheduled annotations is not enough to support horizontal scaling. Indeed, for each instance sharing the same launch configuration, a @Scheduled method will trigger its task as many times as there are instances running.
To solve that, the classic approach would be to use a queue. One task scheduler sends the tasks info in a queue and multiple consumers poll this queue to execute the tasks. Depending on the load, more or fewer consumer instances are launched.
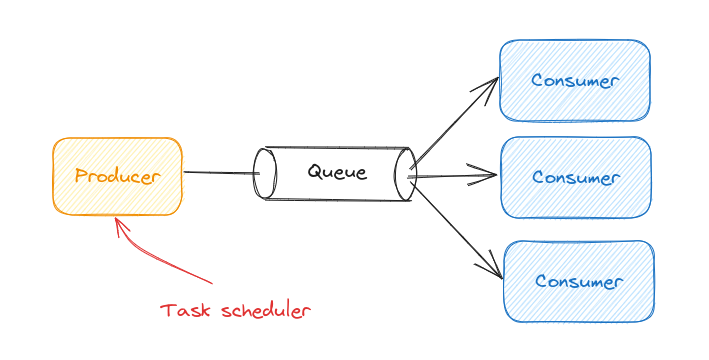
While this architecture is certainly a good choice, it may not fit your technical constraints and needs. This also obliges you to bring the concept of messaging to your project.
In this article, we will see how we can rethink this challenge by avoiding relying on a Publisher-Consumers architecture but by relying on a relational database and its locking mechanisms.
Let’s rethink the problematic
What are we trying to achieve here?
We want:
- to make sure that the tasks run once;
- to trigger those tasks periodically;
- to distribute the load between consumers.
Let’s see how we can achieve that using Spring Boot and a relational database.
Step 1: Defining the consumer tasks
We first need to define the tasks. We create a service containing one method per identified task.
@Configuration
@EnableScheduling
public class TaskScheduler {
@Scheduled(fixedDelay = 5, timeUnit = TimeUnit.MINUTES)
public void scrapSourceWebsite() {
// ...
}
@Scheduled(fixedDelay = 10, timeUnit = TimeUnit.MINUTES)
public void moveDeletedToColdStorage() {
// ...
}
// Other tasks
}
Notice that those methods are launched periodically using the @Scheduled annotation. At each run, the method will check if the task associated with the method can be executed.
The period can be 30 seconds, 5 minutes, or even a CRON expression. Depending on your business needs.
We will come back to the implementation of the methods later.
Step 2: Defining the DB entries
Now that we have defined our service tasks, we can start defining our DB table and entries.
CREATE TABLE task_lock
(
task_id VARCHAR(64) NOT NULL,
last_execution bigint DEFAULT 0 NOT NULL,
PRIMARY KEY (task_id)
);
INSERT INTO task_lock (task_id) VALUES ('scrap_website');
INSERT INTO task_lock (task_id) VALUES ('move_to_cold');
Our table is composed of the task ID and the timestamp of the last execution. This timestamp will be used to evaluate the time since the last execution, thus defining when the task needs to be executed again. We have one row per task, those are the rows that the instance running the task will lock during the time of execution.
Step 3: Implementing the locking query
This third step is about being able to effectively lock a row of the table using JPA annotations. Locking this row will have as effect that any other query will not be able to retrieve it. Meaning that the other service instances will not be able to acquire the lock.
@Repository
public interface TaskLockRepository extends JpaRepository<TaskLockEntity, String> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@QueryHints({
@QueryHint(name = "jakarta.persistence.lock.timeout", value = "1000")
})
Optional<ProviderLockEntity> findByTaskIdAndLastExecutionLessThan(String taskId, long timestamp);
}
We use a pessimistic write lock. When acquired, the lock will stay alive during the time of the transaction. If not acquired, the query will return an empty optional. When trying to acquire a lock, a timeout can be used to define the maximum time a query will wait for a lock to be released (1 second in our example).
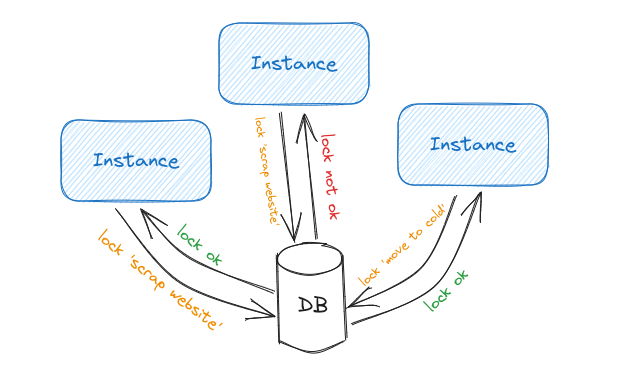
Let’s suppose that we have 2 instances running:
- scrap_website is ready to be executed;
- instance 1 executes the scheduled method
scrapSourceWebsite(); - Instance 1 queries the database and locks “scrap_website”;
- instance 2 executes the scheduled method
scrapSourceWebsite(); - Instance 2 queries the database and gets no results because it cannot lock the already locked row.
Step 4: Linking everything together
Now that we have our main components and the repository, it’s time to write down our task-scheduling logic. Let’s come back to our entry component.
@Configuration
@EnableScheduling
public class TaskScheduler {
private final TaskLockRepository taskLockRepository;
// Other dependencies
public TaskScheduler(TaskLockRepository taskLockRepository) {
this.taskLockRepository = taskLockRepository;
}
@Transactional
@Scheduled(fixedDelay = 5, timeUnit = TimeUnit.MINUTES)
public void scrapSourceWebsite() {
long currentTime = System.currentTimeMillis();
long scheduledRate = Duration.of(1, ChronoUnit.HOURS).toMillis(); // 1h
taskLockRepository.findByTaskIdAndLastExecutionLessThan("scrap_website", currentTime - scheduledRate)
.ifPresent(scrapingTask -> {
// Execute scraping task...
scrapingTask.setLastExecution(System.currentTimeMillis());
});
}
@Transactional
@Scheduled(fixedDelay = 10, timeUnit = TimeUnit.MINUTES)
public void moveDeletedToColdStorage() {
long currentTime = System.currentTimeMillis();
long scheduledRate = Duration.of(6, ChronoUnit.HOURS).toMillis(); // 6h
taskLockRepository.findByTaskIdAndLastExecutionLessThan("move_to_cold", currentTime - scheduledRate)
.ifPresent(moveToCold -> {
// Execute migration of deleted to cold storage...
moveToCold.setLastExecution(System.currentTimeMillis());
});
}
// Other tasks
}
As stated above, the query needs to run in a transaction.
You need to define the period associated with the task (scheduledRate). Respectively 1 and 6 hours in our example. You should use configuration properties if you want to do it the nice way.
This period and the current timestamp will be used to determine if the task can be picked. If the row is already locked or if the last execution time is too close, the instance will not acquire the lock and the method will end.
On the other hand, if the lock is acquired, the task is executed and the timestamp of this execution is saved in the task entity.
What if the task fails?
The transaction will rollback, nothing will be saved, and the lock will be released. Then another instance will be able to require the lock and retry the task.
Depending on your business, you may need to disable a task for a given time if a failure occurs. You will need to handle the error within the transaction.
Example of deactivating a task during 3 hours:
public class TaskScheduler {
// dependencies
@Transactional
@Scheduled(fixedDelay = 5, timeUnit = TimeUnit.MINUTES)
public void scrapSourceWebsite() {
long currentTime = System.currentTimeMillis();
long scheduledRate = Duration.of(1, ChronoUnit.HOURS).toMillis();
taskLockRepository.findByTaskIdAndLastExecutionLessThanAndDeactivatedUntilLessThan("scrap_website", currentTime - scheduledRate, currentTime)
.ifPresent(scrapingTask -> {
try {
// Execute scraping task...
scrapingTask.setLastExecution(System.currentTimeMillis());
} catch (Esception e) {
// Deactivating for 3 hours
scrapingTask.setDeactivatedUntil(System.currentTimeMillis() + Duration.of(3, ChronoUnit.HOURS).toMillis()); // 3h
}
});
}
// Other tasks
}
Side note: When your query method begins to be this long (63 characters 🤯), you should consider rewriting it into JPQL or hiding it behind another method.
What if the instance fails and crashes?
This could happen but we are still safe. The worker will stop responding to the database. The transaction will time out in the database and the lock will be released. How much time will it take? It depends on your database configuration.
How to monitor the instances load?
Monitoring the instance load is crucial to determine if more or fewer instances need to be launched. One way is to use a ThreadPoolTaskExecutor to launch the tasks. Then you need to monitor this ThreadPoolTaskExecutor to get the current number of tasks being executed among all the instances.
Combined with a good monitoring system, Micrometer’s metrics will be your best allies here.
What if we need parameters to those tasks?
Indeed, the example is very simple. In real conditions, you could have parameters for those tasks, tasks that need to run the night only, etc. The principle stays the same as long as you lock the row associated with the task.
Suppose we have a scraping task that needs a website in parameter. We will have this table:
| Website | Last execution timestamp |
|---|---|
| amazom.com | 1234 |
| bol.com | 1267 |
The SQL query simply needs to find the first row and order by the timestamp (amazom.com). Then, the first row being already locked, the next first visible row will be bol.com.
Compared to the Producer-Consumer approach
Let’s take a step back and compare the Locking Task Scheduling to the classic Producer-Consumer.
Pros:
- Easy to put in place if you already have a SQL database;
- No need to add the messaging concept to the stack;
- Error outcome is easy to handle.
Cons:
- No task payload, limited number of parameters;
- Require locking capabilities on database.
Wrap up
We saw an approach to implementing a task-scheduling based on database locks. While this technique is not meant to completely replace the producer-consumer method, it proposes another way of tackling similar challenges. This other way of tackling the challenge offers different possibilities and can give you more flexibility on task definition and scheduling.
Whether you pick Producer-Consumers or Locking Task Scheduler architecture, choosing the right implementation is a risky task. That kind of implementation risk can be mitigated using the Onion Architecture. In a previous article, I explained how you can implement this architecture in Spring Boot projects.